Automating Game of Thrones Data Exploration with LLM and Pandas
Objective
In this experiment, we aimed to simplify the process of exploring Game of Thrones episode data by allowing users to ask questions in plain English. The idea is to remove the need for manually writing queries or understanding the underlying data structure.
Solution Approach
Explore the Code: You can find the Jupyter notebook and all the code used for this experiment on the GitHub repository here. Feel free to clone the repo and dive into the details!
We leveraged the following tools to achieve this:
- LangChain: A framework for building LLM-based applications.
- Pandas: A powerful Python library for data manipulation and analysis.
- OpenAI LLM Model: For natural language understanding and query generation.
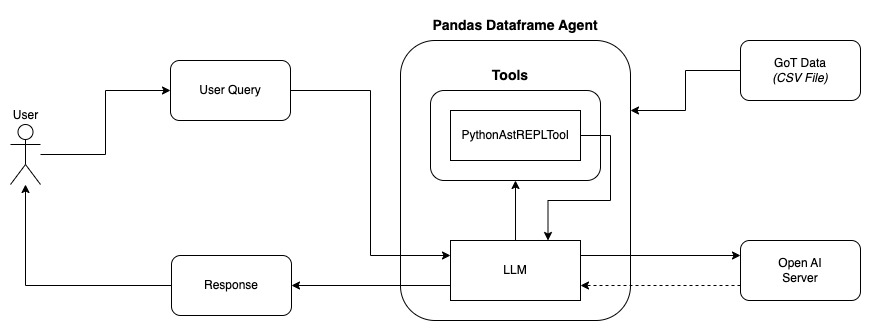
Here’s the core setup:
from langchain_openai import ChatOpenAI
from langchain_experimental.agents import create_pandas_dataframe_agent
import pandas as pd
df = pd.read_csv("data/got_data.csv")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent_executor = create_pandas_dataframe_agent(
llm,
df,
agent_type="tool-calling",
verbose=True,
allow_dangerous_code=True
)
result = agent_executor.invoke({
"input": "How many seasons and episodes are present?"
})
This setup enables the user to ask natural language questions and receive meaningful answers based on the Game of Thrones episode data.
Hypothesis
We hypothesize that any task solvable with Pandas DataFrame APIs can now be automated using the create_pandas_dataframe_agent. The aim is to let users ask questions in plain English and get detailed, descriptive responses. Moreover, the LLM is expected to handle misspellings or varied phrasing, eliminating the need for complex rule-based query parsing.
Experiment: Testing User Queries
To test this, we formulated a few end-user queries of varying complexity.
1. Query: “Tell me about season 1, episode 4”
Expected Output:
Episode Title: "Cripples, Bastards, and Broken Things"
Director: Brian Kirk
Writer: Bryan Cogman
Air Date: May 8, 2011
US Viewers: 2.45 million
Runtime: 56 minutes
IMDB Rating: 8.8
Death Count: 1
Plot: Eddard investigates Jon Arryn's murder...
Pandas DataFrame query by LLM:
df[df['Season'] == 1][df['Episode Number'] == 4]
Observed Output: The response was accurate, providing all requested details, confirming the LLM effectively generated the correct Pandas query to retrieve data.
2. Query: “Tell me about episode 6”
Expected Output: The system should ask for clarification, since there are multiple episode 6’s across seasons.
Pandas DataFrame query by LLM:
df.iloc[5]
Observed Output: Surprisingly, the LLM defaulted to season 1, likely due to conversational context. This highlights an issue with maintaining user session context.
Lesson: Starting a fresh session produced same result, we enabled debugging to further investigate how the LLM interpreted the query.
import langchain
langchain.debug = True
Debugging revealed that the LLM was only exposed to a small slice of the data (only headers and first 5 rows), which explains its failure to ask a clarification question.
3. Query: “Tell me about the Game of thrones, winer is comig”
Expected Output: It should recognize the query refers to “Winter Is Coming”, the first episode of season 1, and handle the misspelling.
Pandas DataFrame query by LLM:
df[df['Episode Name'] == 'Winter Is Coming']
Observed Output: The LLM correctly identified the episode despite the typos, showcasing its ability to interpret user input with minor errors.
4. Query: “In which episode did Ned die?”
Expected Output: The LLM should infer from the episode descriptions and return that Ned Stark dies in “Baelor”.
Pandas DataFrame query by LLM:
df[df['Notable Death Count'] > 0]
Observed Output: The LLM correctly responded, but the query it used (df[df['Notable Death Count'] > 0]) didn’t seem capable of finding that information. It’s likely the LLM used its pre-existing knowledge about the show, hinting at some level of hallucination.
Test: To investigate further, we added a fictional character’s death to see if the LLM would fabricate responses.
- After adding “Rahul” to an episode’s notable death count, the LLM hallucinated by mentioning his death in multiple episodes. This indicated that the LLM was not entirely reliant on the provided dataset and was hallucinating details.
5. Query: “How many views did GOT s2e5 get?”
Expected Output: The viewership data for season 2, episode 5 should be returned.
Pandas DataFrame query by LLM:
df[df['Season'] == 2][['Episode Number', 'Episode Name']]
Observed Output: The LLM struggled and inaccurately claimed there was no data for that episode. This was due to misinterpretation of the column headers in the DataFrame.
Justifications and Debugging
We observed that the LLM was only exposed to partial data due to limitations in how the tool handled large datasets. It often defaulted to interpreting the data based on past context or general knowledge from its training, which led to hallucinations. Debugging with langchain.debug revealed key insights into the prompts passed to the LLM, helping us understand its behavior better.
Tokens and Costs
The experiment ran over multiple queries, with the following token usage and costs:
- Total Tokens: 25,799
- Input Tokens: 24,212
- Output Tokens: 1,587
- Number of OpenAI Requests: 28
- Total Cost: $0.02
Conclusion
Our experiment demonstrated that using Langchain and Pandas for LLM-driven data exploration can automate complex data querying tasks. While the system was able to handle several queries well, it sometimes relied too much on pre-trained knowledge, leading to hallucinations.
The next step is to enhance the system’s handling of larger datasets by refining how it accesses and processes data. Additionally, tools like LangSmith could offer deeper insights into how prompts are structured, aiding in better prompt design and troubleshooting.